
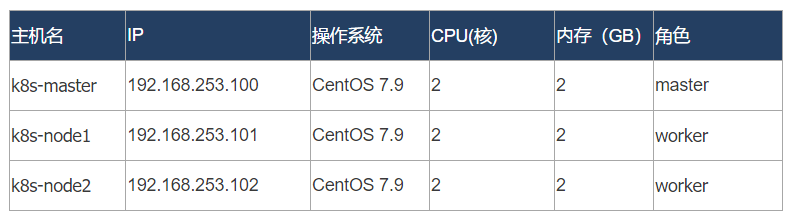
1、准备3台虚拟机
192.168.253.100
192.168.253.101
192.168.253.102
由于k8s在内核3.10下有bug,一定要更新到4.4以上。
升级CentOS7内核至5.4
(1)下载内核源:rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
(2)安装最新版本内核:yum --enablerepo=elrepo-kernel install -y kernel-lt
(3)查看可用内核:cat /boot/grub2/grub.cfg |grep menuentry
(4)设置开机从新内核启动:grub2-set-default “CentOS Linux (5.4.186-1.el7.elrepo.x86_64) 7 (Core)”
(5)查看内核启动项:grub2-editenv list
(6)重启系统:reboot
(7)查看内核版本是否生效:uname -r
2、关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
3、关闭selinux
sed -i ‘s/enforcing/disabled/’ /etc/selinux/config
setenforce 0
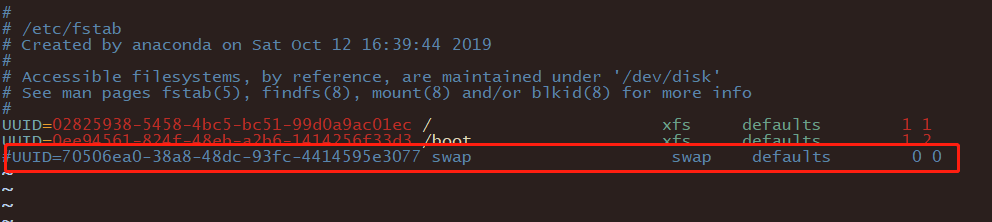
4、关闭swap
swapoff -a
vim /etc/fstab
注释掉swap所在配置
5、添加hosts
cat >> /etc/hosts <<EOF
192.168.253.100 k8s-master
192.168.253.101 k8s-node1
192.168.253.102 k8s-node2
EOF
6、桥接ip流量到iptables
vi /etc/sysctl.conf
net.ipv4.ip_forward = 1
vm.swappiness = 0
sysctl -p
cat >/etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
7、时间同步
yum install ntpdate -y
ntpdate time.windows.com
8、docker安装
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum makecache fast
yum -y install docker-ce
systemctl enable docker && systemctl start docker
配置国内镜像
mkdir -p /etc/docker
tee /etc/docker/daemon.json <<-‘EOF’
{
“registry-mirrors”: [“https://ehbu9xsm.mirror.aliyuncs.com”]
}
EOF
systemctl daemon-reload
systemctl restart docker
9、添加kubernates源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
10、安装kubeadm,kubelet和kubectl
说明:
kubeadm:初始化集群,管理集群等。
kubelet:用于接收api-server指令,对pod生命周期进行管理。
kubectl:集群命令行管理工具。
yum install -y kubelet-1.21.0 kubeadm-1.21.0 kubectl-1.21.0
systemctl enable kubelet
可选项-tab补全
yum install bash-completion -y
source <(kubectl completion bash)
source <(kubeadm completion bash)
vi .bashrc 将下列命令加最后
source <(kubectl completion bash)
source <(kubeadm completion bash)
11、部署kubernetes master
在master上执行
kubeadm init --apiserver-advertise-address=192.168.253.100 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.21.0 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16 --ignore-preflight-errors=all
• --apiserver-advertise-address集群通告地址
• --image-repository由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里指定阿里云镜像仓库地址
• --kubernetes-versionK8s版本,与上面安装的一致
• --service-cidr集群内部虚拟网络,Pod统一访问入口
• --pod-network-cidrPod网络,与下面部署的CNI网络组件yaml中保持一致
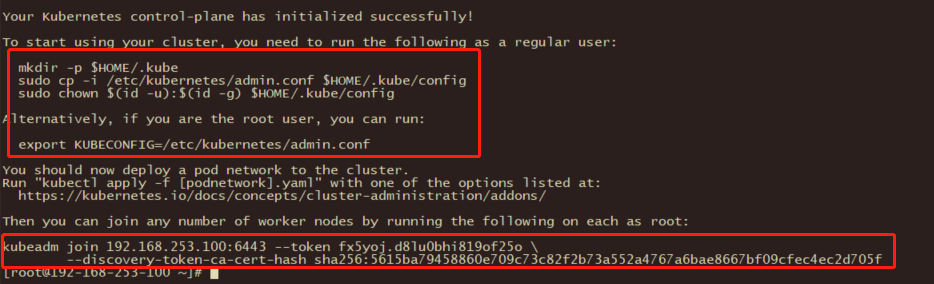
第一个框master执行
第二个框成员加入集群执行
默认token有效期为24小时,当过期之后,该token就不可用了。这时就需要重新创建token,可以直接使用命令快捷生成:
kubeadm token create --print-join-command
12、部署容器网络(CNI)
Calico是一个纯三层的数据中心网络方案,是目前Kubernetes主流的网络方案。
下载YAML:wget https://docs.projectcalico.org/manifests/calico.yaml --no-check-certificate
下载完后还需要修改里面定义Pod网络(CALICO_IPV4POOL_CIDR),与前面kubeadm init的 --pod-network-cidr指定的一样。

修改完后文件后,在master部署:
kubectl apply -f calico.yaml
kubectl get pods -n kube-system
等Calico Pod都Running,节点也会准备就绪。
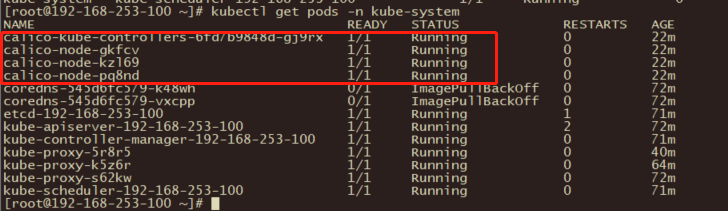
13、在所有节点上安装coredns
docker pull registry.aliyuncs.com/google_containers/coredns:1.8.0
docker tag registry.aliyuncs.com/google_containers/coredns:1.8.0 registry.aliyuncs.com/google_containers/coredns/coredns:v1.8.0

kubectl get pods -n kube-system
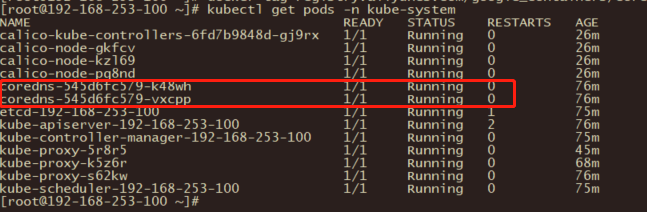
14、各组件重启服务
【MASTER端+NODE共同服务】
systemctl restart etcd
systemctl daemon-reload
systemctl enable flanneld
systemctl restart flanneld
【MASTER端独有服务】
systemctl daemon-reload
systemctl enable kube-apiserver
systemctl restart kube-apiserver
systemctl daemon-reload
systemctl enable kube-controller-manager
systemctl restart kube-controller-manager
systemctl daemon-reload
systemctl enable kube-scheduler
systemctl restart kube-scheduler
【NODE端独有服务】
systemctl daemon-reload
systemctl enable kubelet
systemctl restart kubelet(status状态为 not ready时候重启即可)
systemctl daemon-reload
systemctl enable kube-proxy
systemctl restart kube-proxy
【查看服务状态】
systemctl status etcd
systemctl status flanneld
systemctl status kube-apiserver
systemctl status kube-controller-manager
systemctl status kube-scheduler
systemctl status kubelet
systemctl status kube-proxy
遇到的问题:
(1)error execution phase kubelet-start: error uploading crisocket: timed out waiting for the condition
To see the stack trace of this error execute with --v=5 or higher
解决方式:
swapoff -a
kubeadm reset
systemctl daemon-reload
systemctl restart kubelet
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
(2)dial tcp 127.0.0.1:10251: connect: connection refused
执行kubectl get cs检测组件健康状态时,出现下面的问题:

解决方式:
修改/etc/kubernetes/manifests下的 kube-controller-manager.yaml 和 kube-scheduler.yaml 两个文件,只是掉-port=0 这一行,然后重启kubelet
systemctl restart kubelet
再测试下kubectl get cs,发现正常了。

(3)在worker节点上运行:kubectl get nodes命令时,出现如下错误:
The connection to the server localhost:8080 was refused - did you specify the right host or port?
解决方法:
在当前用户的HOME目录下创建.kube目录,然后再把master节点的$HOME/.kube/config拷贝过来
mkdir .kube
scp master@192.168.253.100:/root/.kube/config /root/.kube/
然后再执行kubectl get nodes命令就正常了。

