
一、背景
HPA全称是Horizontal Pod Autoscaler,直译过来是Pod水平自动伸缩器。HPA是k8s弹性伸缩的重要功能,它支持在应用资源消耗量很大的情况下,根据用户配置的阈值进行自动扩容,从而减少人工介入。
二、原理
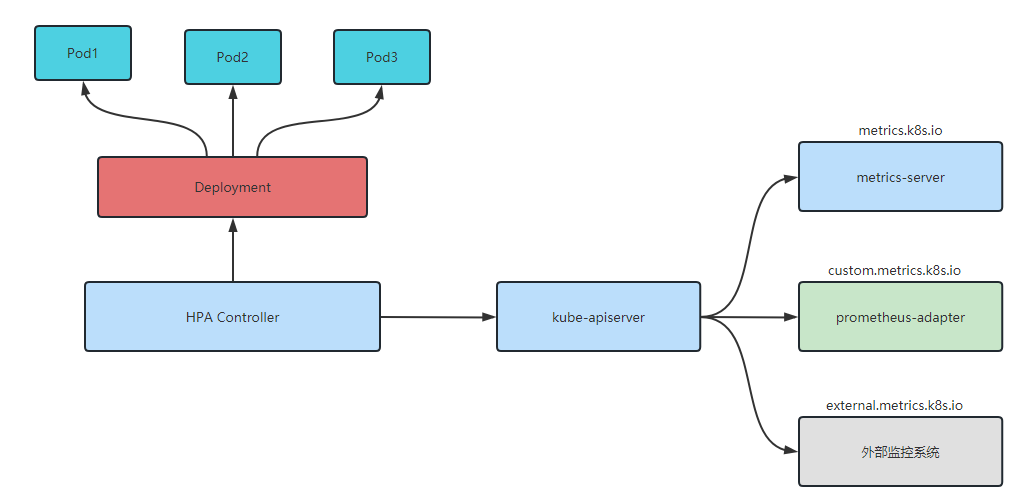
HPA通过HPA Controller定时对应用进行动态扩缩容,默认是15秒,可以通过启动k8s时配置 --horizontal-pod-autoscaler-sync-period 参数指定周期。
HPA执行步骤如下:
(1)HPA Controller每隔15秒进行一次流程,先获取用户定义的HPA规则,然后通过aggregator层(kube-apiserver)请求metrics-server获取CPU/Memory指标。
(2)metrics-server定时从kubelet获取应用指标情况。
(3)HPA Controller根据CPU/Memory指标计算新的Pod副本数,并修改Deployment的replicas数值。
(4)Deployment Controller监控到副本数的变化,执行Pod的扩缩容动作。
三、简单使用
1、安装metrics-server
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.2/components.yaml
验证是否安装成功:kubectl top node
[root@k8s-master1 metrics-server-0.4.x]# kubectl top node
W1223 15:27:19.880509 93982 top_node.go:119] Using json format to get metrics. Next release will switch to protocol-buffers, switch early by passing --use-protocol-buffers flag
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master1 263m 13% 1432Mi 50%
k8s-node1 169m 8% 790Mi 42%
2、创建Deployment
Deployment的配置内容如下,通过kubectl apply -f xxx.yml执行创建。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
查看创建结果
[root@k8s-master1 deployments]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 1/1 1 1 96s
[root@k8s-master1 deployments]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-585449566-7dn6n 1/1 Running 0 74s
为了测试效果更明显,手动调整deployment的硬件资源,在.spec.template.spec.containers.resources添加如下配置,然后:wq保存退出。
resources:
requests:
cpu: 5m
memory: 50Mi
3、创建HPA
kubectl autoscale deployment nginx-deployment --cpu-percent=10 --min=1 --max=3
说明:
(1) --min=1:最小的副本数1个
(2)–max=3:最大的副本数3个
(3)–cpu-percent=10: CPU阈值,10%。
查看hpa: kubectl get hpa
[root@k8s-master1 deployments]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-deployment Deployment/nginx-deployment <unknown>/10% 1 3 0 5s
4、压测
临时启动一个busybox容器:kubectl run -it --image busybox test-hpa --restart=Never --rm /bin/sh
在容器内执行下面命令进行压测:
while true; do wget -q -O- http://172.16.36.80 >/dev/null; done
观察Pod的变化
[root@k8s-master1 deployments]# kubectl top pod
W1223 16:06:52.230360 128889 top_pod.go:140] Using json format to get metrics. Next release will switch to protocol-buffers, switch early by passing --use-protocol-buffers flag
NAME CPU(cores) MEMORY(bytes)
nginx-deployment-7dcd754485-rn6wq 127m 7Mi
nginx-deployment-7dcd754485-xclzd 0m 3Mi
test-hpa 610m 2Mi
[root@k8s-master1 deployments]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-deployment Deployment/nginx-deployment 1270%/10% 1 3 3 7m3s
[root@k8s-master1 deployments]# kubectl describe hpa nginx-deployment
Name: nginx-deployment
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Fri, 23 Dec 2022 15:59:54 +0800
Reference: Deployment/nginx-deployment
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 1150% (57m) / 10%
Min replicas: 1
Max replicas: 3
Deployment pods: 3 current / 3 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited True TooManyReplicas the desired replica count is more than the maximum replica count
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedGetResourceMetric 6m50s (x2 over 7m6s) horizontal-pod-autoscaler failed to get cpu utilization: did not receive metrics for any ready pods
Warning FailedComputeMetricsReplicas 6m50s (x2 over 7m5s) horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: did not receive metrics for any ready pods
Normal SuccessfulRescale 2m48s horizontal-pod-autoscaler New size: 2; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 43s horizontal-pod-autoscaler New size: 3; reason: cpu resource utilization (percentage of request) above target
[root@k8s-master1 deployments]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-7dcd754485-pk2gn 1/1 Running 0 46s 172.16.36.84 k8s-node1 <none> <none>
nginx-deployment-7dcd754485-rn6wq 1/1 Running 0 11m 172.16.36.80 k8s-node1 <none> <none>
nginx-deployment-7dcd754485-xclzd 1/1 Running 0 2m51s 172.16.36.83 k8s-node1 <none> <none>
test-hpa 1/1 Running 0 2m58s 172.16.36.81 k8s-node1 <none> <none>
停掉压测脚本,继续观察hpa的输出和pod的变化。
[root@k8s-master1 deployments]# kubectl describe hpa nginx-deployment
Name: nginx-deployment
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Fri, 23 Dec 2022 15:59:54 +0800
Reference: Deployment/nginx-deployment
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 0% (0) / 10%
Min replicas: 1
Max replicas: 3
Deployment pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale recommended size matches current size
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited True TooFewReplicas the desired replica count is less than the minimum replica count
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedGetResourceMetric 13m (x2 over 14m) horizontal-pod-autoscaler failed to get cpu utilization: did not receive metrics for any ready pods
Warning FailedComputeMetricsReplicas 13m (x2 over 14m) horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: did not receive metrics for any ready pods
Normal SuccessfulRescale 9m43s horizontal-pod-autoscaler New size: 2; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 7m38s horizontal-pod-autoscaler New size: 3; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 76s horizontal-pod-autoscaler New size: 1; reason: All metrics below target
[root@k8s-master1 deployments]# kubectl top pod
W1223 16:14:18.214740 5638 top_pod.go:140] Using json format to get metrics. Next release will switch to protocol-buffers, switch early by passing --use-protocol-buffers flag
NAME CPU(cores) MEMORY(bytes)
nginx-deployment-7dcd754485-rn6wq 0m 8Mi
[root@k8s-master1 deployments]#

