
一、分布式锁
如果多个进程(模块)需要对同一份数据进行修改,这个时候就需要用到分布式锁,保证多个进程串行操作,否则并行修改的数据将出现不可预测的问题。
分布式锁的解决方案有很多,其中常用的一种就是利用redis来实现分布式锁,
主要用到以下两种命令:
(1)setnx
(2)set key value px 毫秒数 nx
由于redis是单线程执行的,所有客户端的操作指令都要排队,因此多个进行执行setnx时,只有第一个成功,其他的都是失败,例如setnx lock:userUpdate true ,redis执行成功时返回1,失败时返回0,那么执行成功的客户端就相当于拿到了锁。
通过setnx命令来实现分布式锁存在锁释放的问题,通常锁的释放有进程自己处理,当业务处理完成之后立马释放锁,同时需要有redis进行保底操作,也就是当客户端还没释放锁之前就宕机了,这个时候可以有redis的超时机制来删除锁。而由于setnx和expire是两条命令,那么这里存在的风险就是当setnx执行完之后还没来得及执行expire之前客户端宕机了,那么就出现死锁了。
基于该问题,redis在2.8版本实现了set key value px 毫秒数 nx命令,也就是retnx+expire为一条命令,不会存在原子操作问题。
对于java客户端,可以用jedis自己实现分布式锁,更多的是用redisson来实现。
二、异步消息队列
在Java进程内,可以用JDK自带的BlockingQueue相关类,比如ArrayBlockingQueue来处理异步消息,由某一个线程生产消息,然后写入BlockingQueue,再有另外一个线程负责消费消息。那么当跨进程时,通过需要用到消息中间件,例如RocketMQ、Kafka等等,但是相对比较重,如果只是简单的使用异步消息,则可以考虑Redis,Redis的list常用于异步消息队列,通过rpush/lpush向list写入消息,通过rpop/lpop向list获取消息。
使用rpop/lpop获取消息有以下缺点:
当Redis的list为空时,rpop/lpop并不会阻塞,但是直接读取空数据,那么这个时候如果客户端不断的遍历读取,CPU会飙高,常见做法是客户端读取到空数据时,通过sleep的方式先休眠一段时间,然后再尝试读取,但这样当有消息时又不能实时获取。有没有类似于BlockingQueue的take()方法那样,当队列为空时,直接阻塞等待。
基于上面的需要,Redis提供了brpop/blpop命令,类似于BlockingQueue的take()方法,当消息队列为空,客户端阻塞等待。
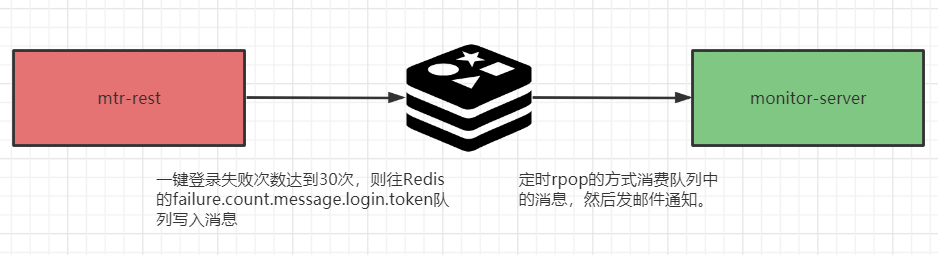
【发布订阅】
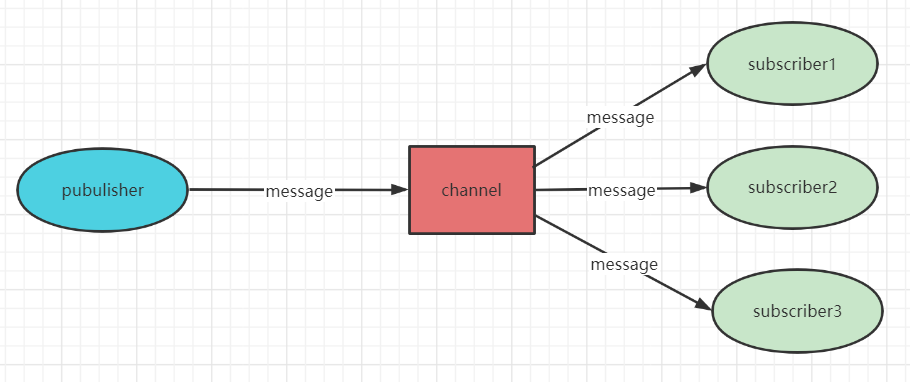
redis支持消息发布订阅模式,主要操作如下:
127.0.0.1:6379> publish news hahaha # 往频道news发布一条消息,如果频道不存在则创建
(integer) 2
---------------------------
127.0.0.1:6379> subscribe news # 订阅news频道,客户端会阻塞
Reading messages... (press Ctrl-C to quit)
1) "subscribe" # 类型:subscribe、psubscribe、message
2) "news"
3) (integer) 1
1) "message" # 消息
2) "news" # 频道
3) "hahaha" # 内容
127.0.0.1:6379> subscribe news new1 new2 # 批量订阅多个频道
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "news"
3) (integer) 1
1) "subscribe"
2) "new1"
3) (integer) 2
---------------------------
127.0.0.1:6379> psubscribe new* # 模式订阅,也就是通过正则表达的方式批量订阅多个频道
Reading messages... (press Ctrl-C to quit)
1) "psubscribe"
2) "new*"
3) (integer) 1
---------------------------
127.0.0.1:6379> unsubscribe news # 取消订阅
1) "unsubscribe"
2) "news"
3) (integer) 0
127.0.0.1:6379> punsubscribe new* # 取消模式订阅
1) "punsubscribe"
2) "new*"
3) (integer) 0
---------------------------
127.0.0.1:6379> pubsub channels # 查看活跃频道,所谓活跃频道,就是至少有一个订阅者,而且是通过subscribe方式订阅,不能是psubscribe的方式。
1) "news"
2) "new1"
127.0.0.1:6379> pubsub numsub news # 查看频道news的订阅数
1) "news"
2) (integer) 1
127.0.0.1:6379> pubsub numpat # 查看psubscribe方式订阅的订阅数
(integer) 1
说明一下:unsubscribe和punsubscribe通过redis-cli根本没用,因此订阅的时候客户端是阻塞的,如果断开了,redis会自动剔除该客户端的订阅。
redis发布订阅有一个致命的缺点,就是消息丢失,如果客户端宕机重启了,那么在宕机期间发布的所有消息对于该客户端来说永久丢失,基于此缺点,其实redis的发布订阅功能实际应用不多。
【Stream】
Redis Stream是在5.0发布的功能,主要解决Redis的发布订阅功能消息丢失的问题。是Redis实现消息队列比较完善的实现方案,主要实现的功能包括:
- 消息ID的序列化生产
- 消息遍历
- 消息的阻塞和非阻塞读取
- 消息的分组消费
- 未完成消息处理
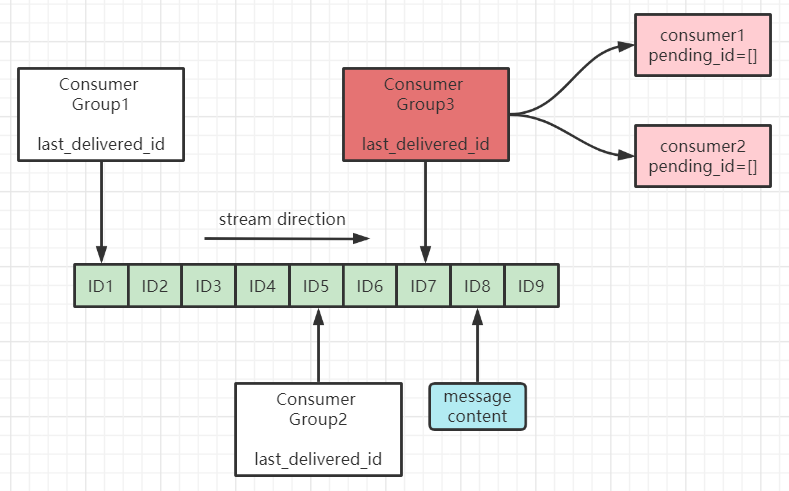
Consumer Group:消费者组,可以简单看成记录流状态的一种数据结构。消费者既可以选择使用 XREAD 命令进行 独立消费,也可以多个消费者同时加入一个消费者组进行 组内消费。同一个消费者组内的消费者共享所有的 Stream 信息,同一条消息只会有一个消费者消费到,这样就可以应用在分布式的应用场景中来保证消息的唯一性。
last_delivered_id:用来表示消费者组消费在 Stream 上 消费位置 的游标信息。每个消费者组都有一个 Stream 内 唯一的名称,消费者组不会自动创建,需要使用 XGROUP CREATE 指令来显式创建,并且需要指定从哪一个消息 ID 开始消费,用来初始化 last_delivered_id 这个变量。
pending_ids:每个消费者内部都有的一个状态变量,用来表示 已经 被客户端 获取,但是 还没有 ack 的消息。记录的目的是为了 保证客户端至少消费了消息一次,而不会在网络传输的中途丢失而没有对消息进行处理。如果客户端没有 ack,那么这个变量里面的消息 ID 就会越来越多,一旦某个消息被 ack,它就会对应开始减少。这个变量也被 Redis 官方称为 PEL (Pending Entries List)。
消息队列操作:
127.0.0.1:6379> xadd messages * msg1 111 # xadd 往队列的队尾添加消息, * 表示由redis自动生成消息ID,ID格式为时间戳 - 序号
"1636448765690-0"
127.0.0.1:6379> xadd messages * msg2 222
"1636448769726-0"
127.0.0.1:6379> xadd messages * msg3 333
"1636448773573-0"
127.0.0.1:6379> xlen messages #xlen 返回队列长度
(integer) 3
127.0.0.1:6379> xrange messages - + # xrange 查询队列,-表示从头 +表示结尾
1) 1) "1636448765690-0"
2) 1) "msg1"
2) "111"
2) 1) "1636448769726-0"
2) 1) "msg2"
2) "222"
3) 1) "1636448773573-0"
2) 1) "msg3"
2) "333"
127.0.0.1:6379> xdel messages 1636448765690-0 # 删除队列中消息项
(integer) 1
127.0.0.1:6379> xlen messages
(integer) 2
127.0.0.1:6379>
独立消息消费操作:
127.0.0.1:6379> xread count 1 block 0 streams messages 1636448769726-0 # 从 1636448769726-0开始读取下一个消息,如果消息不存在则阻塞
1) 1) "messages"
2) 1) 1) "1636448773573-0"
2) 1) "msg3"
2) "333"
127.0.0.1:6379> xread count 1 block 0 streams messages $ # 从队列最后一位开始读取下一个消息,如果消息不存在则阻塞
1) 1) "messages"
2) 1) 1) "1636448995820-0"
2) 1) "msg4"
2) "444"
(20.27s) # 表示阻塞了多长时间
消费组消费操作:
127.0.0.1:6379> xgroup create messages cg1 0-0 # 创建消费组cg1,并指定last_delivered_id的位置从第一个消息开始
OK
127.0.0.1:6379> xgroup create messages cg2 $ # 创建消费组cg2,并指定last_delivered_id的位置从最后一个消息开始
OK
127.0.0.1:6379> xreadgroup group cg1 c1 count 1 block 0 streams messages > # 消费组cg1创建消费者c1 读取下一个消息
1) 1) "messages"
2) 1) 1) "1636448769726-0"
2) 1) "msg2"
2) "222"
127.0.0.1:6379> xreadgroup group cg1 c2 count 1 block 0 streams messages > # >表示获取last_delivered_id的下一个消息,每当消费者读取一条消息,last_delivered_id也会同步前进。
1) 1) "messages"
2) 1) 1) "1636448773573-0"
2) 1) "msg3"
2) "333"
127.0.0.1:6379> xinfo consumers messages cg1 # 查看消费组信息
1) 1) "name"
2) "c1"
3) "pending"
4) (integer) 1
5) "idle"
6) (integer) 22323
2) 1) "name"
2) "c2"
3) "pending"
4) (integer) 1
5) "idle"
6) (integer) 14338
127.0.0.1:6379> xreadgroup group cg1 c2 count 1 block 0 streams messages 1636448769726-0 # 指定消息
1) 1) "messages"
2) 1) 1) "1636448773573-0"
2) 1) "msg3"
2) "333"
127.0.0.1:6379> xack messages cg1 1636448769726-0 # 响应消息已处理
(integer) 1
127.0.0.1:6379> xack messages cg1 1636448773573-0
(integer) 1
127.0.0.1:6379> xreadgroup group cg1 c2 count 1 block 0 streams messages 1636448769726-0 # xack后再获取该消息的话就拿不到了。如果消费者在xack之前宕机,重启之后可以通过pending_ids列表重新读取消息,然后再处理。
三、位图
位图并不是Redis的一种数据结构,实际上就是字符串,对字符串的位进行操作,位图是直接修改bit的值,而一个bit只有1和0两个值,因此通常存放的是boolean型的数据,放在具体的业务中,通常就是由true/false两种状态的业务,比如点赞、签到、在线等,常见的应用常见有:网站用户签到天数统计、网站日活/月活、网站在线人数统计等等。
常见操作:
- setbit key offset value : 对key的第offset位的值设置为value
- getbit key offset : 读取key的第offset位的值
- bitcount key [start end] : 统计key中多几个1
- bitpos key bit [start] [end] : 读取key中第一个bit(1/0)出现的位置
- bitop operation destKey key [key …] : 对多个key进行元数据操作,包括AND/OR/NOT/XOR,把运算结果写到destKey
127.0.0.1:6379> setbit s 2 1
(integer) 1
127.0.0.1:6379> getbit s 2
(integer) 1
127.0.0.1:6379> bitcount s
(integer) 1
127.0.0.1:6379> bitpos key 1
(integer) -1
127.0.0.1:6379> bitpos key 0
(integer) 0
127.0.0.1:6379> setbit s 3 1
(integer) 0
127.0.0.1:6379> bitpos s 1
(integer) 2
127.0.0.1:6379> setbit t 0 1
(integer) 0
127.0.0.1:6379> bitop or d s t
(integer) 1
127.0.0.1:6379> bitcount d
(integer) 3
127.0.0.1:6379>
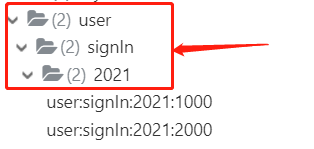
(1)网站用户签到天数统计
记录一年中每个用户的签到情况,key设计为:user:signIn:2021:1000,其中最后一位是用户ID,user:signIn为签到业务,2021为年份,一年按366天记录,当ID为1000的用户1月1日签到时,执行的命令为setbit user:signIn:2021:1000 0 1, 当ID为1000的用户1月2日签到时,执行的命令为setbit user:signIn:2021:1000 1 1, 以此类推。
127.0.0.1:6379> setbit user:signIn:2021:1000 0 1 # ID为1000的用户1月1日签到
(integer) 0
127.0.0.1:6379> setbit user:signIn:2021:1000 1 1 # ID为1000的用户1月2日签到
(integer) 0
127.0.0.1:6379> setbit user:signIn:2021:1000 5 1 #ID为1000的用户 1月6日签到
(integer) 0
127.0.0.1:6379> bitcount user:signIn:2021:1000 # 统计ID为1000的用户签到天数
(integer) 3
127.0.0.1:6379> setbit user:signIn:2021:2000 2 1 # ID为2000的用户1月3日签到
(integer) 0
127.0.0.1:6379> setbit user:signIn:2021:2000 3 1 # ID为2000的用户1月4日签到
(integer) 0
127.0.0.1:6379> bitcount user:signIn:2021:2000 # 统计ID为2000的用户签到天数
(integer) 2
127.0.0.1:6379> keys user:signIn:2021* # 遍历2021年所有有签到记录的用户
1) "user:signIn:2021:2000"
2) "user:signIn:2021:1000"
127.0.0.1:6379>
Redis的Key命名规范:业务模块名: 业务逻辑含义: 其他,比如上面的user:signIn:2021:2000,通过key的名字大概知道缓存数据的业务含义,而且通过redis 客户端展示有层次结构。
(2)网站日活/月活
统计网站日活,一般是以具体某一天作为key,把用户ID作为offset,例如:user:dau:20211012 , 用户ID为10, 则可以执行如下命令:setbit user:dau:20211012 10 1 ,其中DAU为Daily Active User(日活跃用户)。
127.0.0.1:6379> setbit user:dau:20211012 10 1 # ID为10的用户是2021年10月12日的活跃用户
(integer) 0
127.0.0.1:6379> setbit user:dau:20211012 11 1 # ID为11的用户是2021年10月12日的活跃用户
(integer) 0
127.0.0.1:6379> setbit user:dau:20211012 20 1 # ID为20的用户是2021年10月12日的活跃用户
(integer) 0
127.0.0.1:6379> bitcount user:dau:20211012 # 统计2021年10月12日的活跃用户数
(integer) 3
127.0.0.1:6379>
使用该方式统计网站日活有一定的提前条件,也就是用户ID在数据库是自增连续的,否则不适合上面的方式。统计网站月活的方式跟统计日活非常类似,只是key设计为按月为单位,例如:user:mau:202110 (注:MAU=Monthly Active User 月活跃用户)
四、HyperLogLog(UV统计)
有时候需要对网站页面访问量进行统计,通常由PV(Page View)和UV(User View),PV的统计比较简单,累加即可,而对于UV的统计则需要去重操作,也就是相同用户多次访问,UV只算1次。
对于PV的统计,Redis很容易就可以实现,通过incrby命令可以进行累加操作,例如
127.0.0.1:6379> incrby pv:index.html:20211012 1 # 设置index.html在20211012的pv为1
(integer) 1
127.0.0.1:6379> get pv:index.html:20211012
"1"
那么对于UV的统计,就不能简单的进行incrby操作了,因为还需要去重,常见的方案有如下方式
(1)set
使用set数据结构来存储访问的用户ID,利用set去重的特点,从而达到统计UV的效果。
127.0.0.1:6379> sadd uv:index.html:20211012 10
(integer) 1
127.0.0.1:6379> sadd uv:index.html:20211012 11
(integer) 1
127.0.0.1:6379> sadd uv:index.html:20211012 12
(integer) 1
127.0.0.1:6379> scard uv:index.html:20211012
(integer) 3
统计的时候通过scard命令,统计set的元素数量,即可得出UV。当数据量比较小的时候,使用该方案比较简单。但是当数据量比较大,比较占内存,因此比较少用。
(2)位图
使用位图来存放访问的用户ID,同样可以达到统计UV的效果,把用户ID作为offset设置值为1,由于位图设置的幂等性,相同用户多次设置时,只是记录1次。
127.0.0.1:6379> setbit uv:index.html:20211012 10 1
(integer) 0
127.0.0.1:6379> setbit uv:index.html:20211012 11 1
(integer) 0
127.0.0.1:6379> setbit uv:index.html:20211012 12 1
(integer) 0
127.0.0.1:6379> bitcount uv:index.html:20211012
(integer) 3
通过位图的方式统计UV要比set方式占用的内存小得多。
(3)HyperLogLog
由于UV的统计并不需要非常精准,统计结果100万跟101万对于老板来说并无太大差别,基于此,对于UV的统计非常适用HyperLogLog,HyperLogLog提供了不精准的统计方案,其误差率在0.81%左右,但仅仅占用12KB的内存,因此非常贴合我们的需求。
127.0.0.1:6379> pfadd uv:index.html:20211012 10
(integer) 1
127.0.0.1:6379> pfadd uv:index.html:20211012 11 12
(integer) 1
127.0.0.1:6379> pfcount uv:index.html:20211012
(integer) 3
上面的操作非常类似set,通过pfadd命令添加元素,通过pfcount统计总量。
五、布隆过滤器
Redis并不能直接使用布隆过滤器,需要安装插件RedisBloom,安装过程如下:
(1)下载安装包:https://github.com/RedisBloom/RedisBloom/tags
(2)解压安装:解压缩之后进入到RedisBloom目录下执行make即可,安装成功可以看到 redisbloom.so文件

(3)把 redisbloom.so的绝对路径配置到Redis的配置文件redis.conf中,在redis.conf添加如下配置:
loadmodule /usr/local/RedisBloom-2.2.6/redisbloom.so

(4)重启redis即可
有一个这样的应用场景,新闻客户端在向你推荐新闻时,首先需要判断你是否已经阅读过该新闻,如果你已经看过了,则不推荐。基于以上的需求,可以怎么实现呢?
方案一:
查数据库的新闻阅读记录,如果能查得到的话,则表明已阅读,否则可以推荐。这种实现方式在数据量比较少的情况下是可行的,但是如果数据量比较大,那么数据库的压力会非常大,有可能被压垮。
方案二:
把个人的新闻阅读记录存放在Redis的set上,推荐时与Redis上的记录进行匹配。这种实现方式相对于数据库的方式好一些,减轻了数据库压力,但是消耗了比较多的内存。
方案三:
利用Redis位图的功能,把个人的新闻阅读记录进行hash取模,然后存入到位图上,推荐时进行hash匹配。这种实现方式相对于方案二,可以大大减少内存。
那么有没有更好的方案呢?利用布隆过滤器可以更好的实现,布隆过滤器是在方案三的基础上进行优化,其思想是【宁可错杀三千,不会放过一人】,也就是布隆过滤器判断不存在的肯定不存在,判断存在的,可能存在,也可能不存在。而且存在一定的误差率,误差率是可控的。
这比较符合新闻推荐的需求,不会存在重复推荐的情况,虽然可能存在漏推的情况,但这可以接收。
布隆过滤器的常见操作如下:
127.0.0.1:6379> bf.reserve records 0.1 10000 # 创建一个records布隆过滤器,指定误差率为0.1,初始长度为10000,默认误差率为0.01,初始长度为100
OK
127.0.0.1:6379> bf.add records java # 添加元素
(integer) 1
127.0.0.1:6379> bf.madd records c++ golang python # 批量添加元素
1) (integer) 1
2) (integer) 1
3) (integer) 1
127.0.0.1:6379> bf.exists records java # 判断元素是否存在
(integer) 1
127.0.0.1:6379> bf.mexists records java java1 java2 # 批量判断元素是否存在
1) (integer) 1
2) (integer) 0
3) (integer) 0
布隆过滤器的实现原理:
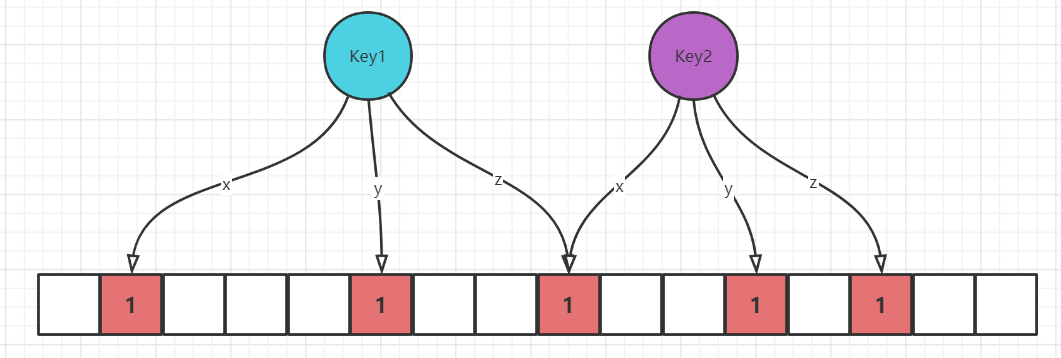
布隆过滤器底层就是一个位数据和几个hash函数,向布隆过滤器添加key时,布隆过滤器根据几个哈市函数对key进行hash,算出一个整数索引值再根据数组长度进行取模得出对应数据下标位置,然后把该下标的值设置为1。判断是否存在的时候,用同样的过程从对应下标的数组读取值,所有下标对应的值是1,则判断存在,否则就是不存在。
我们在创建一个布隆过滤器的时候: bf.reserve records 0.1 10000,我们在创建布隆过滤器的时候,可以指定误差率。那么布隆过滤器是怎么控制误差率的呢?有如下公式:
k=0.7*(length/n) # 约等于
f=0.6185^(length/n) # ^ 表示次方计算,也就是 math.pow
上面length表示位数据长度,n表示预估元素个数,k表示函数的个数,f表示误差率。
从公式中可以看出
位数组相对越长 (length/n),错误率 f 越低,这个和直观上理解是一致的
位数组相对越长 (length/n),hash 函数需要的最佳数量也越多,影响计算效率
当一个元素平均需要 1 个字节 (8bit) 的指纹空间时 (length/n=8),错误率大约为 2%
错误率为 10%,一个元素需要的平均指纹空间为 4.792 个 bit,大约为 5bit
错误率为 1%,一个元素需要的平均指纹空间为 9.585 个 bit,大约为 10bit
错误率为 0.1%,一个元素需要的平均指纹空间为 14.377 个 bit,大约为 15bit
六、限流
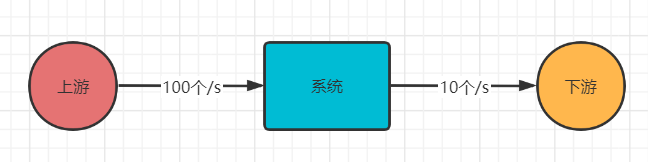
当系统的上游下发请求的速度超过下游处理的速度时,系统需要对上游进行限流处理。在5G消息网关中,在ChannelServer模块可以看到限流的操作,主要是用来防止过快拉取RocketMQ的消息,当运营商处理消息的速度低于ChannelServer拉取RocketMQ消息中速度时,ChannelServer进行限流。限流通过是在单位时间内最大请求量的限制,那么怎么利用Redis进行限流呢?
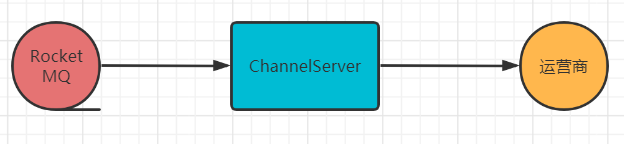
(1)限流算法
常见的限流算法有:漏桶算法和令牌桶算法
(a)漏桶算法
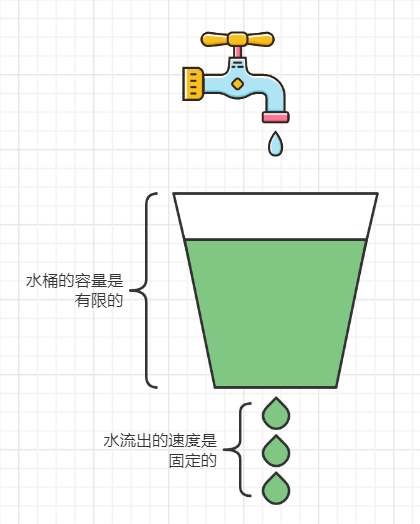
水桶的容量是有限的,且水流出的速度是固定的,当水流入(请求)的速度超过水流出的速度时,水桶装满溢出,则直接拒绝请求,漏桶算法可以强制执行处理速率,也就是无论水桶中水量多少,其流出的速度不会变。
(b)令牌桶算法
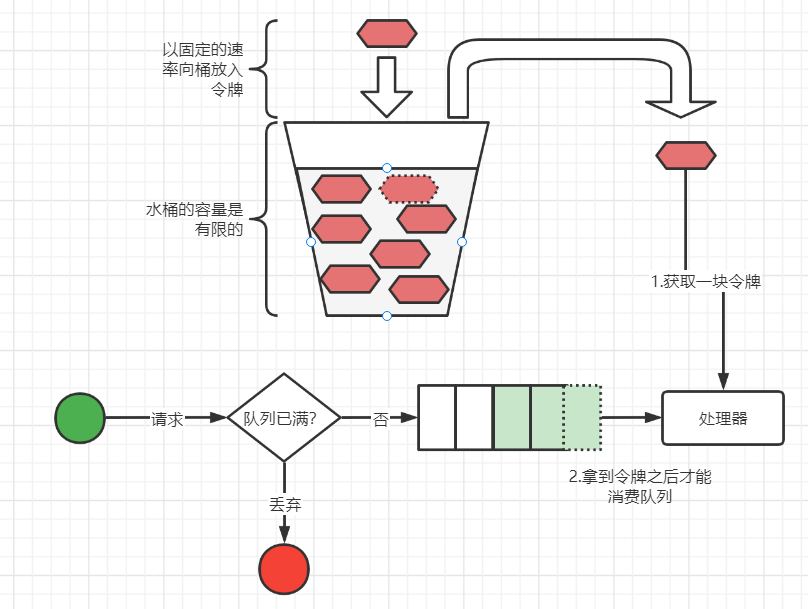
令牌桶算法跟漏桶算法相反,以固定的速率向桶放入令牌,当处理器要处理请求时,先从令牌桶中获取一块令牌,拿到令牌之后才能从请求队列中处理一个请求。对于外部请求来说,如果请求队列已满了,那么将请求丢弃。由于令牌桶算法对于消费令牌的速率没有限制,因此比较适合流量突发的情况。
(2)简单限流
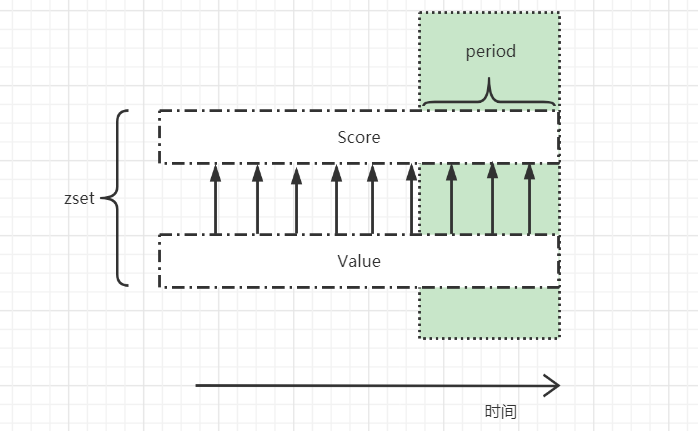
利用zset的特点,其中zset的元素数量可以判断请求总数,score用于处理过期请求。
主要思路如下:
a. 清除zset中过期的请求记录,利用zremrangebyscore,例如zremrangebyscore key1 0 current - period,一般情况下请求处理时间要小于period。
b. 设置key的expire过期时间,一般设置为period + 1000(单位毫秒),如果period没有请求,则key自动过期清除。
c. 判断zset的数量是否小于max,如果是,则把请求记录存入zset中。
假设请求的处理效率是一样的,那么上面的方式采用的是漏桶算法。
(3)信号量(Semaphore)限流
信号量有点令牌桶的味道,不同的是,信号量用于控制客户端的并发数量,客户端在处理请求时,先从申请一个信号量,拿到信号量之后进行业务处理,完了之后把信号量释放。
Redis实现信号量利用的是整数value值,例如
a. 初始化信号量:set semaphore 10
b. 获取一个信号量:decr semaphore
c. 释放一个信号量: incr semaphore
对应的客户端redisson有相关的功能:
RSemaphore semaphore = redisson.getSemaphore("semaphore");
//设置资源数量 只需要设置一次
semaphore.trySetPermits(3);
//请求资源 默认获取一个,可以自己一次获取多个
semaphore.acquire();
//释放资源
semaphore.release();
七、GeoHash
我们经常通过美团/饿了么找附近的餐厅,这涉及到地理位置的查询,Redis在3.2版本上线了地址位置GEO模块,那么基于Redis,我们也可以进行地理位置查找了。
地图元素的位置数据采用二维经纬度来表示,经纬为(-180, 180],纬度为(-90, 90]。比如玄武科技总部坐标为:113.327178,23.140911 ,表示经度113.327178,纬度23.140911,那么如何通过经纬度来查询附近的XX呢?
这里会用到GeoHash算法,它的核心思想是把二维空间的经纬度转换为一维的字符串。通过比较字符串来查找附近的XX。
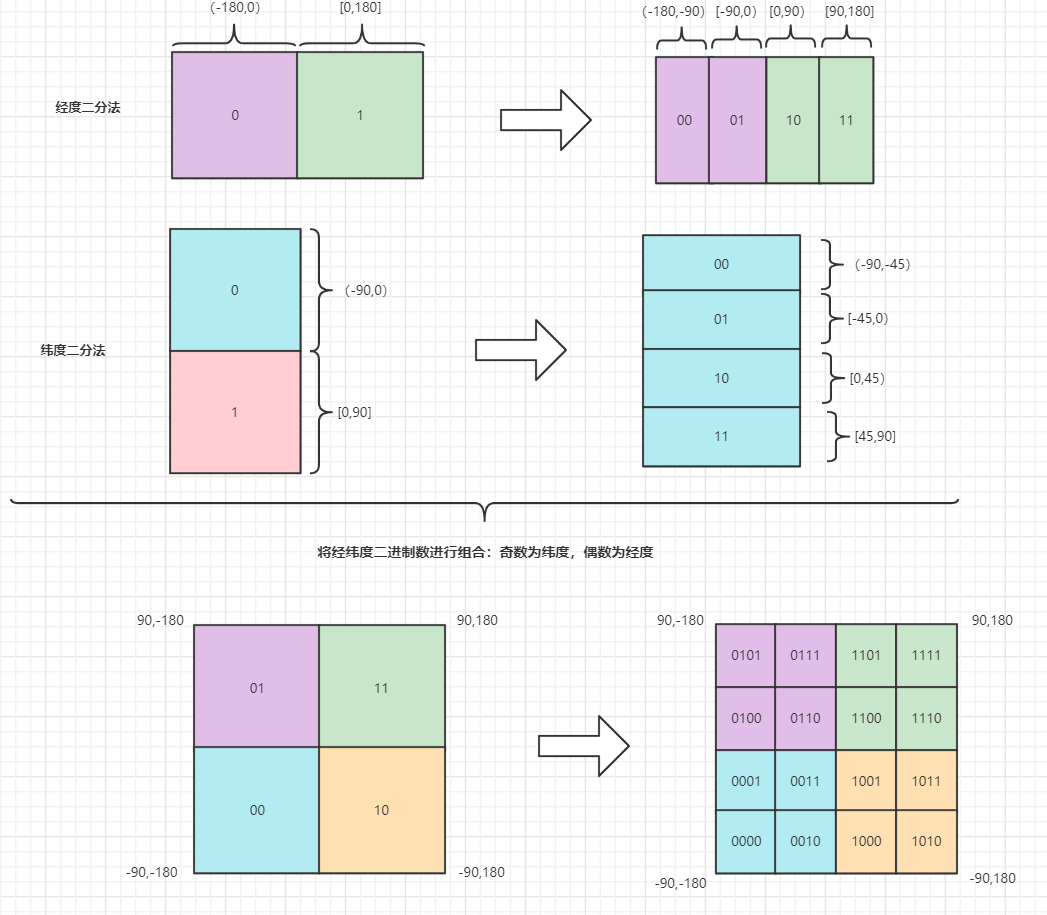
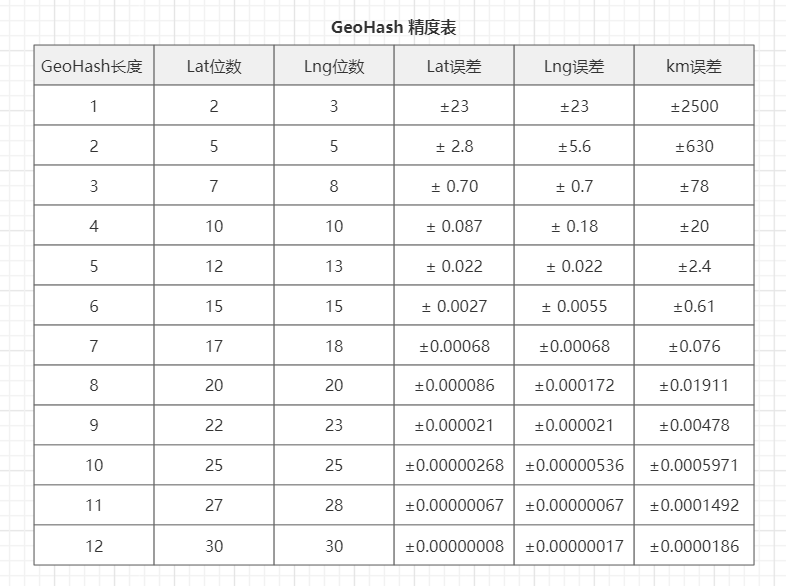
该算法的实现方式是将经度和纬度进行二分法递归分割,如上图所示,分割的次数越多,其区域所在范围越小,分割完成之后再将经纬度二进制数据进行组合,以奇数为纬度,以偶数为经度,之后把组合的数据通过base32 (0-9,a-z 去掉 a,i,l,o 四个字母) 转换为字符串。查找的时候通过比较字符串来实现附近的XX功能,例如:select * from t_position where geohash like ‘w32ba1%’ ,下表是GeoHash精度表,通过GeoHash长度来判断精度,比如附近600m的人,那么通过精度表,地址位置的geohash前6位相同,以此类推。
1、Redis的GEO操作
(1)数据准备
百度地址拾取坐标系统:https://api.map.baidu.com/lbsapi/getpoint/index.html
玄武科技总部(xuanwu) : 113.327178,23.140911
高盛大厦(gaosheng):113.327751,23.141785
天河体育馆(tiyu): 113.329741,23.141128
天河游泳馆(youyong):113.333186,23.140813
(2)添加地理位置
127.0.0.1:6379> geoadd position 113.327178 23.140911 xuanwu
(integer) 1
127.0.0.1:6379> geoadd position 113.327751 23.141785 gaosheng
(integer) 1
127.0.0.1:6379> geoadd position 113.329741 23.141128 tiyu
(integer) 1
127.0.0.1:6379> geoadd position 113.333186 23.140813 youyong
(integer) 1
语法:geoadd key longitude latitude member
(3)计算两点距离
127.0.0.1:6379> geodist position xuanwu youyong m
"614.5899"
127.0.0.1:6379> geodist position xuanwu youyong km
"0.6146"
127.0.0.1:6379>
语法:geodist key member1 member2 [unit]
单位默认为m,其他可选单位有:m、km、mi、ft,分别表示米、千米、英里和尺。
(4)获取元素地理位置
127.0.0.1:6379> geopos position xuanwu
1) 1) "113.32717984914779663"
2) "23.14091045258437163"
127.0.0.1:6379>
语法:geopos key member
(5)获取元素hash值
127.0.0.1:6379> geohash position xuanwu
1) "ws0edudmdd0"
127.0.0.1:6379>
语法:geohash key member
(6)附近的地方
127.0.0.1:6379> georadiusbymember position xuanwu 500 m count 3 asc
1) "xuanwu"
2) "gaosheng"
3) "tiyu"
127.0.0.1:6379> georadiusbymember position xuanwu 500 m withcoord withdist withhash count 3 asc
1) 1) "xuanwu"
2) "0.0000"
3) (integer) 4046534355990050
4) 1) "113.32717984914779663"
2) "23.14091045258437163"
2) 1) "gaosheng"
2) "113.3260"
3) (integer) 4046534356094955
4) 1) "113.32774847745895386"
2) "23.14178493138434334"
3) 1) "tiyu"
2) "262.8301"
3) (integer) 4046534357569308
4) 1) "113.32973867654800415"
2) "23.14112843860407054"
127.0.0.1:6379> georadius position 113.32717 23.140910 1000 m count 4 asc
1) "xuanwu"
2) "gaosheng"
3) "tiyu"
4) "youyong"
127.0.0.1:6379> georadius position 113.32717 23.140910 500 m count 4 asc
1) "xuanwu"
2) "gaosheng"
3) "tiyu"
语法:
(a)georadiusbymember key member radius m|km|mi|ft [withcoord] [withdist] [withhash] [count count] [asc|desc]
(a)georadius key longtitude latitude radius m|km|mi|ft [withcoord] [withdist] [withhash] [count count] [asc|desc]
上面两个指令比较类似,georadiusbymember是通过成员来查询,georadius则是指定坐标地址来查询。
[withcoord] 表示地点的坐标
[withdist] 表示地点的距离
[withhash] 表示地点的hash值
2、Redis的GEO底层数据结构
redis的GEO底层通过zset来存储数据,那么意味着我们通过操作zset的方式来操作position,如下面的操作所示,可以通过zscore position xuanwu来查看某个位置的score,该score代表的是坐标位置的hash值。
127.0.0.1:6379> zrange position 0 -1
1) "xuanwu"
2) "gaosheng"
3) "tiyu"
4) "youyong"
127.0.0.1:6379> zcard position
(integer) 4
127.0.0.1:6379> zscore position xuanwu
"4046534355990050"
127.0.0.1:6379>

